
Foundations #1: The Proposal for Relational Databases

I’m launching a series of posts called “Foundations,” which will present the roots of well-known technologies, patterns, or solutions that quietly revolutionized their fields. Each post will uncover the details that were groundbreaking in their day yet still echo through the systems and software we use today.
If you’re 40 or under, you have probably started your database-related software development learning path with relational databases. And even more, you have worked with relational databases for most of your career without even thinking about it.
But have you ever thought about how the world was before that? Some contextual information at that time:
Hierarchical and network data models dominated, requiring engineers to understand every detail of data storage and access paths.
In the '60s, the cost per megabyte of storage was around $6,000 (yes, six thousand dollars).
Software changes were complex and manual, requiring planning, coding, and manually compiling on mainframes. Debugging could take days, as any minor error required punching code onto cards and rerunning entire programs.
One strong contributor to high costs on software maintenance was how data was organized and accessible. Data management was an inflexible and intricate process. Changing one element, like adding a field or adjusting a data type, often meant reprogramming large portions of the system, which took a long time and cost.
One example is tree-structured files, a hierarchical data model. Programs that consumed this database model would suffer if the file’s structure changed.

Codd mentioned this kind of challenge as “data independence”:
Independence of application programs and terminal activities from growth in data types and changes in data representation--and certain kinds of data inconsistency which are expected to become troublesome even in nondeductive systems.
Based on all these challenges, he presented a data model in June 1970 that offered something transformative for the time: independence from data storage details.
In his article “A Relational Model of Data for Large Shared Data Banks”, Codd discussed the foundation for relational databases and the concept of a universal data sublanguage, which would become the SQL language.
Codd recognized the issue with this heavy data storage dependency and its correlation with data evolution:
Future users of large data banks must be protected from having to know how the data is organized in the machine (the internal representation).
[…] Changes in data representation will often be needed as a result of changes in query, update, and report traffic and natural growth in the types of stored information.
This abstraction was groundbreaking because it removed the need for users and programs to "know" the exact layout or storage mechanisms of data. Instead, they could query data using logical structures without regard for physical order or indexes.
The definition
Codd’s proposal relies on separating the responsibilities of data description from machine representation. This separation could facilitate software maintenance and its impact by allowing users to focus on the necessary parts rather than the whole.
From there, Codd proposed a new way to represent data and its relations through the relational data model.
Codd's concept of a relation is based on the mathematics discipline, alongside concepts such as sets, domains, and degrees, defined in heterogeneous relation.

The idea was that an n-ary relation could be represented through an array of relations. In the example below, there’s a relation “supply” of degree 4, and its rows and domains explicitly identified:
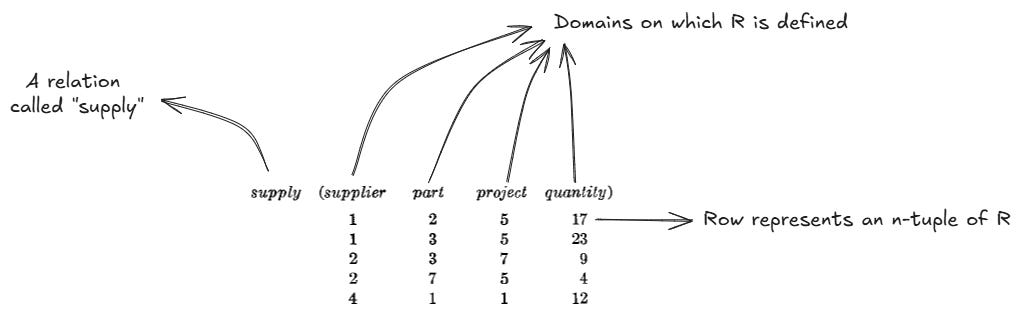
Codd also defined some very familiar concepts throughout his proposal: primary and foreign keys:
One domain (or combination of domains) of a given relation has values which uniquely identify each element (n-tuple) of that relation. Such a domain (or combination) is called a primary key.
We shall call a domain (or domain combination) of relation R a foreign key if it is not the primary key of R but its elements are values of the primary key of some relation S.
Primary keys (PK) and foreign keys (FK) were essential to another concept that Codd introduced: the normal form.
In a nutshell, Codd stated that when in a “complicated data structure”, there was a need to eliminate the nonsimple domains using the process that he called “normalization”, consisting of:
Starting with the relation at the top of the tree, take its primary key and expand each of the immediately subordinate relations by inserting this primary key domain or domain combination.
The primary key of each expanded relation consists of the primary key before expansion augmented by the primary key copied down from the parent relation.
Strike out from the parent relation all nonsimple domains, remove the top node of the tree, and repeat the same sequence of operations on each remaining subtree.
For instance, consider the unnormalized data sets employee, job history, children, and salary history, each with its respective domains:

After applying the normalization form, the set would become:

Of course, this is extremely well-known. Normalization is part of every database course around there. However, at that time, it was crucial to represent complex data structures while keeping the key aspects of the proposal for a relational data model.
The Linguistic Foundations of Relational Databases
The shift to a relational model changed not only how data was organized but also fundamentally how we communicate with data systems. Before Codd's work, interacting with databases required low-level, system-specific commands. The relational model, however, introduced the idea of a universal data sublanguage, which evolved into SQL language.
At its core, this universal language was built on the principles of applied predicate calculus. By employing first-order logic, it offered a framework robust enough to express any valid query or manipulation of relational data.
Once we have characteristics such as domains descriptions, the relations between them, primary and foreign keys, plus normalization process, the use of terms, formulas, quantifiers, and variables, fundamental of predicate calculus, becomes possible, giving space for creating the above-mentioned universal data sublanguage.
The universality of the data sublanguage lies in its descriptive ability.
This was revolutionary: instead of being bound by rigid, system-dependent syntax, users could describe what they wanted without specifying how to get it. Codd’s vision meant that data operations could now focus on intent.
Key features of this linguistic framework included:
Logical Independence: Queries could be written abstractly without regard to the underlying physical structure or storage methods.
Declarative Nature: Users specify desired outcomes (e.g., "retrieve all suppliers for Project X") without detailing the process.
Descriptive Power: The language could handle the complexity of expressing relationships, constraints, and logical dependencies through a single unified syntax.
By separating the description of relationships from their implementation, this approach not only simplified data interactions but also democratized access to powerful database capabilities.
In his paper, Codd didn’t define the SQL language itself. He limited himself to defining the foundation of the data sublanguage but also went through mentioning and relating some operations, such as permutation, projection, and join, that are connected to the usage of predicate calculus and operations regarding sets.
What happened next
Codd’s work was the initial seed for several critical advancements in relational databases, the SQL language, and the establishment of a new paradigm in software development. His paper not only created a revolutionary concept but also set the stage for practical implementations that would define the future of data management.

Following his proposal, Codd continued refining and expanding his ideas, working alongside IBM researchers to transform theory into practice.
One of the most notable projects inspired by his work was System R, an experimental database system developed in the early 1970s. This system was instrumental in proving the viability of the relational model for real-world applications.
System R’s architecture serves as a good example of a real implementation of Codd’s concepts. Codd’s idea of separating data representation from machine representation is clearly stated as the Relational Data Interface (RDI) and Relational Storage Interface (RSI).

From System R’s original paper: “The Relational Data Interface (RDI) is the principal external interface of System R. It provides high level, data independent facilities for data retrieval, manipulation, definition, and control. The data definition facilities of the RDI allow a variety of alternative relational views to be defined on common underlying data”.
And “The Relational Storage Interface (RSI) is an internal interface which handles access to single tuples of base relations. This interface and its supporting system, the Relational Storage System (RSS) , is actually a complete storage subsystem in that it manages devices, space allocation, storage buffers, transaction consistency and locking, deadlock detection, backout, transaction recovery, and system recovery. Furthermore, it maintains indexes on selected fields of base relations, and pointer chains across relations‘.
Codd’s work regarding a “universal data sublanguage” also served as the foundation for SEQUEL (Structured English Query Language), the precursor to SQL. SEQUEL’s design emphasized simplicity and usability, allowing non-specialists to interact with data in previously unimaginable ways.
Building on the success of System R and SEQUEL, IBM released DB2 in the 1980s, the first commercial relational database management system (RDBMS) based on Codd’s relational principles. This marked the beginning of the adoption of relational databases across industries.
Other companies, including Oracle, Sybase, and Informix, followed suit, creating their own RDBMS products that adhered to and expanded upon the relational model. These systems became the backbone of enterprise data management, powering applications from banking systems to e-commerce platforms.
Codd’s influence extended beyond software to shape the culture of database design and development. His principles encouraged a focus on data abstraction, independence, and normalization—concepts that remain at the core of modern database education and practice.